Материалы по тегу: gtc 2024
|
19.03.2024 [22:31], Сергей Карасёв
ASRock Rack представила серверы с поддержкой ускорителей NVIDIA Blackwell и HopperКомпания ASRock Rack на конференции GTC 2024 анонсировала свои самые мощные серверы для обучения ИИ-моделей — системы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200. Кроме того, дебютировали решения с поддержкой новейших ускорителей NVIDIA Blackwell. Серверы 6U8X-EGS2 NVIDIA H100 и 6U8X-EGS2 NVIDIA H200 выполнены в форм-факторе 6U. Они рассчитаны на установку восьми ускорителей NVIDIA H100 и H200 соответственно. Возможно использование двух процессоров Intel Xeon Sapphire Rapids или Xeon Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600, 12 отсеков для SFF-накопителей NVMe с интерфейсом PCIe 5.0 x4 (четыре также имеют поддержку SATA), два коннектора М.2 2280/22110 (PCIe 3.0 x4), восемь слотов HHHL PCIe5.0 x16 и пять слотов FHHL PCIe5.0 x16. Питание обеспечивают восемь блоков мощностью 3000 Вт с сертификатом 80 PLUS Platinum/Titanium. ASRock Rack также представила двухсокетный barebone-сервер 4UMGX с поддержкой восьми ускорителей NVIDIA H100 NVL или H200 в форм-факторе 4U. Система может комплектоваться шестью DPU NVIDIA BlueField-3 или шестью сетевыми адаптерами NVIDIA ConnectX-7. Модель 4UMGX также поддерживает ускорители NVIDIA Blackwell. В основу сервера положена модульная архитектура NVIDIA MGX, предназначенная для создания ИИ-систем на базе CPU, GPU и DPU. 
Источник изображений: ASRock Rack Кроме того, дебютировали двухсокетные 4U серверы 4U8G-EGS2, 4U10G-EGS2, 4U8G-GENOA2 и 4U10G-GENOA2. Первые два рассчитаны на чипы Intel Xeon Sapphire Rapids или Xeon Emerald Rapids, два других — на процессоры AMD EPYC 9004 (Genoa). Они могут оснащаться ускорителями NVIDIA H100 NVL и H200 NVL, а в перспективе — NVIDIA Blackwell. Устройства 4U8G поддерживают восемь двухслотовых карт FHFL с интерфейсом PCIe 5.0 x16, решения 4U10G — десять. Intel-системы снабжены 32 слотами для модулей памяти DDR5, AMD-модели — 24-мя.  ASRock Rack также готовит суперускоритель GB200 NVL72, серверы с поддержкой конфигурации NVIDIA HGX B200 8-GPU и другие решения на основе аппаратных компонентов NVIDIA.
19.03.2024 [03:18], Владимир Мироненко
Всё своё ношу с собой: NVIDIA представила контейнеры NIM для быстрого развёртывания оптимизированных ИИ-моделейКомпания NVIDIA представила микросервис NIM, входящий в платформу NVIDIA AI Enterprise 5.0 и предназначенный для оптимизации запуска различных популярных моделей ИИ от NVIDIA и её партнёров. NVIDIA NIM позволяет развёртывать ИИ-модели в различных инфраструктурах: от локальных рабочих станций до облаков. Предварительно созданные контейнеры и Helm Chart'ы с оптимизированными моделями тщательно проверяются и тестируются на различных аппаратных платформах NVIDIA, у поставщиков облачных услуг и на дистрибутивах Kubernetes. Это обеспечивает поддержку всех сред с ускорителями NVIDIA и гарантирует, что компании смогут развёртывать свои приложения генеративного ИИ где угодно, сохраняя полный контроль над своими приложениями и данными, которые они обрабатывают. Разработчики могут получить доступ к моделям посредством стандартизированных API, что упрощает разработку и обновление приложений. 
Источник изображений: NVIDIA NIM также может использоваться для оптимизации исполнения специализированных решений, поскольку не только использует NVIDIA CUDA, но и предлагает адаптацию для различных областей, таких как большие языковые модели (LLM), визуальные модели (VLM), а также модели речи, изображений, видео, 3D, разработки лекарств, медицинской визуализации и т.д. NIM использует оптимизированные механизмы инференса для каждой модели и конфигурации оборудования, обеспечивая наилучшую задержку и пропускную способность и позволяя более просто и быстро масштабироваться по мере роста нагрузок. 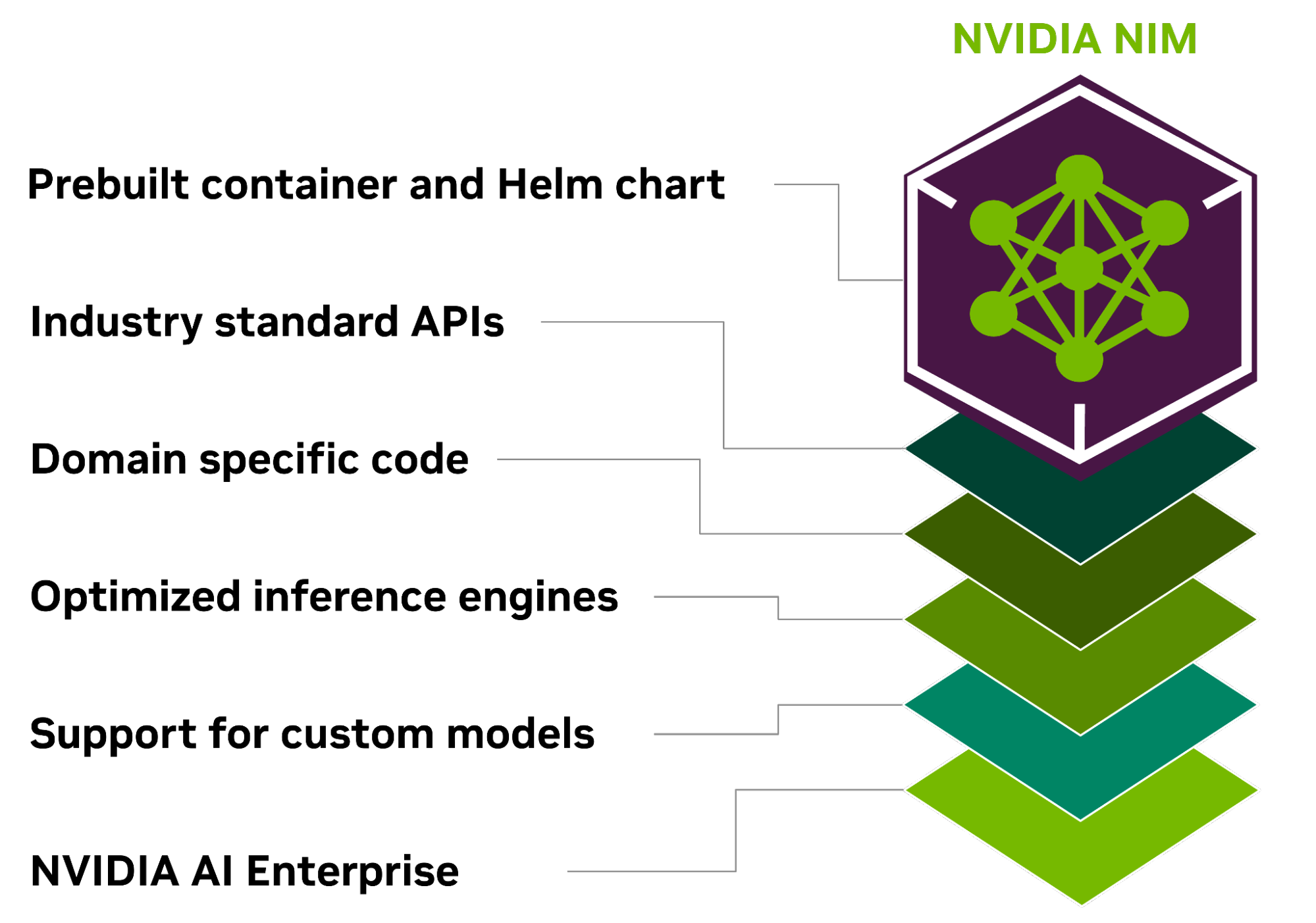 В то же время NIM позволяет дообучить и настроить модели на собственных данных, поскольку можно не только воспользоваться облачными API NVIDIA для доступа к готовым моделями, но и самостоятельно развернуть NIM в Kubernetes-средах у крупных облачных провайдеров или локально, что сокращает время разработки, сложность и стоимость подобных проектов и позволяет интегрировать NIM в существующие приложения без необходимости глубокой настройки или специальных знаний.
19.03.2024 [02:16], Владимир Мироненко
NVIDIA AI Enterprise 5.0 предложит микросервисы, которые ускорят развёртывание ИИNVIDIA представила свежую версию платформы для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров для быстрого развёртывания приложений генеративного ИИ. NVIDIA отметила, что уже микросервисы адаптируются ведущими поставщиками ПО и платформ кибербезопасности, а все функции AI Enterprise 5.0 вскоре будут доступны в облачных маркетплейсах AWS, Google Cloud, Microsoft Azure и Oracle Cloud. Микросервисы позиционируются компанией как эффективный инструмент для создания разработчиками современных корпоративных приложений в глобальном масштабе. Работая прямо в браузере, разработчики могут используют для создания приложений облачные API. NVIDIA AI Enterprise 5.0 теперь включает предназначенные для развёртывания моделей ИИ микросервисы NIM и микросервисы CUDA-X. Сюда входит и NVIDIA cuOpt, ИИ-микросервис для задачи логистики, который позволяет значительно ускорить оптимизации маршрута и расширить возможности динамического принятия решений, снижая затраты, экономя время и позволяя сократить выбросы CO2. 
Источник изображения: NVIDIA NIM оптимизирует инференс-нагрузки для различных популярных моделей ИИ от NVIDIA и партнёров. Используя ПО NVIDIA для инференса, включая Triton Inference Server, TensorRT и TensorRT-LLM, NIM позволяет сократить развёртывание моделей с недель до минут и вместе с тем обеспечивает безопасность и управляемость в соответствии с отраслевыми стандартами, а также совместимость с инструментами управления корпоративного уровня. В настоящее время компания работает над расширением возможностей AI Enterprise. С выходом версии NVIDIA AI Enterprise 5.0 платформа получила ряд дополнений. В частности, она теперь включает NVIDIA AI Workbench, набор инструментов для разработчиков, обеспечивающих быструю загрузку, настройку и запуск проектов генеративного ИИ. ПО теперь общедоступно и поддерживается NVIDIA. NVIDIA AI Enterprise 5.0 также теперь поддерживает платформу Red Hat OpenStack. Кроме того, в NVIDIA AI Enterprise 5.0 расширена поддержка широкого спектра новейших ускорителей NVIDIA, сетевого оборудования и ПО для виртуализации.
19.03.2024 [01:40], Сергей Карасёв
NVIDIA запустила облачную платформу Quantum Cloud для квантово-классического моделированияКомпания NVIDIA объявила о запуске платформы облачных микросервисов Quantum Cloud, которая поможет учёным и разработчикам проводить исследования в сфере квантовых вычислений для различных областей, включая химию, биологию и материаловедение. В основу Quantum Cloud легла NVIDIA CUDA Quantum — открытая платформа, предназначенная для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Она даёт возможность выполнять сложные симуляции квантовых схем. На базе микросервисов Quantum Cloud пользователи смогут непосредственно в облаке создавать и тестировать новые квантовые алгоритмы и приложения. Это могут быть, в частности, гибридные квантово-классические системы. Утверждается, что Quantum Cloud обладает развитыми возможностями и поддерживает интеграцию стороннего ПО для ускорения научных исследований. 
Источник изображения: NVIDIA В состав Quantum Cloud входит компонент Generative Quantum Eigensolver, разработанный в сотрудничестве с Университетом Торонто: он использует большие языковые модели (LLM), позволяющие квантовому компьютеру быстрее находить энергию основного состояния молекулы. Интеграция решений израильского стартапа Classiq помогает исследователям создавать большие и сложные квантовые программы, а также проводить глубокий анализ квантовых схем. В свою очередь, инструмент QC Ware Promethium решает сложные задачи квантовой химии, такие как молекулярное моделирование. «Квантовые системы представляют собой следующий революционный рубеж в сфере вычислений. Quantum Cloud устраняет барьеры на пути изучения этой преобразующей технологии и позволяет любому учёному в мире использовать возможности квантовых вычислений и воплощать свои идеи в реальность», — говорит Тим Коста (Tim Costa), руководитель NVIDIA по направлению HPC и квантовых вычислений.
19.03.2024 [01:37], Сергей Карасёв
NVIDIA и Siemens внедрят генеративный ИИ в промышленное проектирование и производство
gtc 2024
nvidia
omniverse
siemens
software
ии
облако
производство
промышленность
разработка
цифровой двойник
Компании NVIDIA и Siemens сообщили о расширении сотрудничества с целью внедрения иммерсивной визуализации и генеративного ИИ в промышленное проектирование и производство. В частности, Siemens интегрирует новый программный интерфейс NVIDIA Omniverse Cloud API в свою платформу Xcelerator. Напомним, Omniverse Cloud представляет собой комплексный пакет облачных сервисов, позволяющих проектировать, публиковать, эксплуатировать и тестировать приложения метавселенной вне зависимости от местонахождения. В свою очередь, Xcelerator — интегрированный пакет ПО и сервисов для разработки приложений. NVIDIA и Siemens совмещают платформы Omniverse и Xcelerator, выводя промышленную автоматизацию на новый уровень. Партнёры объединяют обширную промышленную экосистему Xcelerator и физически точный механизм создания виртуального мира в реальном времени с поддержкой ИИ. Это позволяет создавать точные реалистичные цифровые двойники. 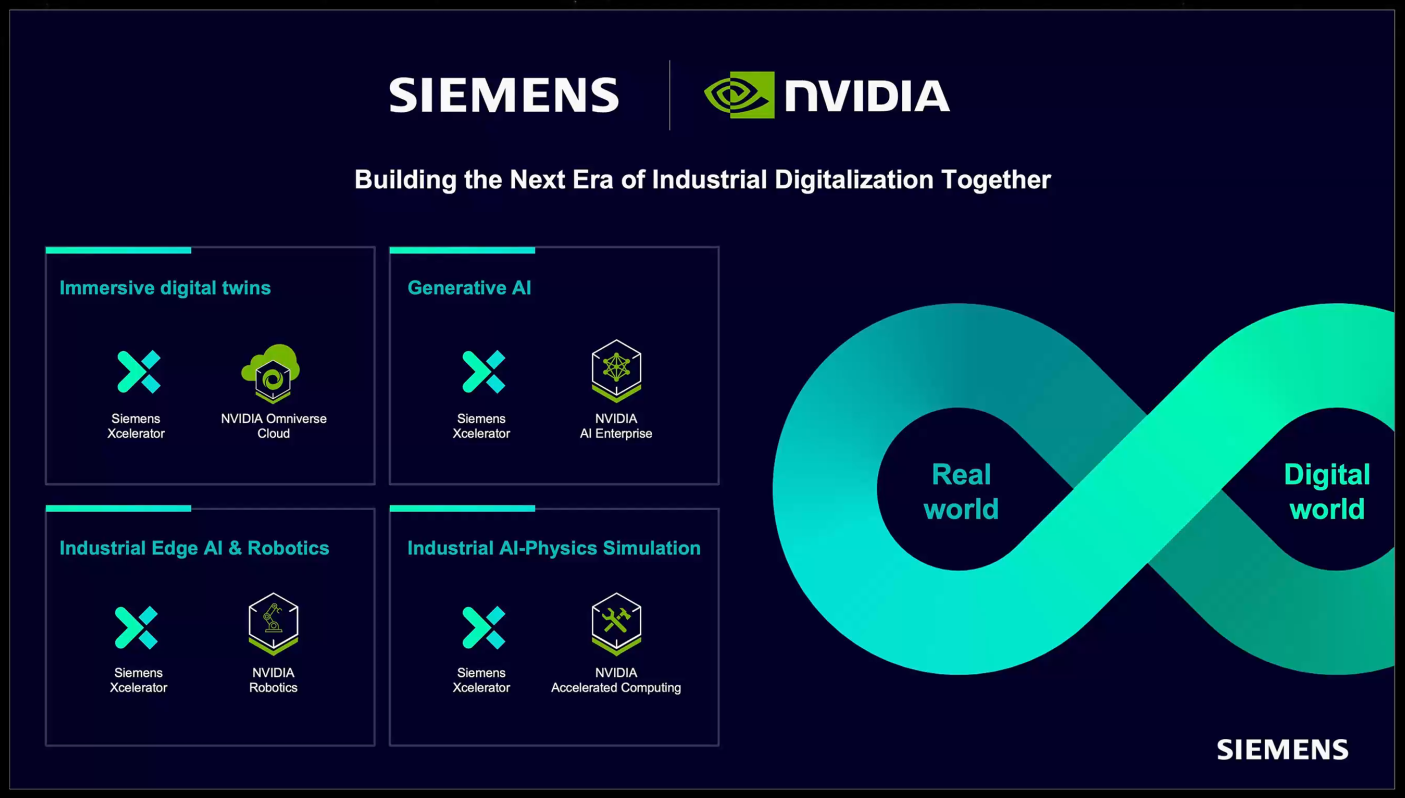
Источник изображения: NVIDIA В рамках сотрудничества Siemens, в частности, интегрирует NVIDIA Omniverse Cloud API в состав Teamcenter X (входит в Xcelerator). Облачная система Teamcenter X предоставляет пользователям безопасный доступ к данным управления жизненным циклом изделия (PLM) из любой точки мира, с любого устройства и в любое время. Благодаря использованию API Omniverse могут быть ускорены различные рабочие процессы при создании цифровых двойников, такие как изменение условий освещения, применение тех или иных материалов и пр. 
Источник изображения: NVIDIA Отмечается, что традиционно компании в значительной степени полагались на физические прототипы при реализации крупномасштабных промышленных проектов. Такой подход является дорогостоящим, ограничивает инновации и замедляет время выхода решений на рынок. Совместная инициатива Siemens и NVIDIA позволяет устранить указанные препятствия путём создания фотореалистичных цифровых двойников, учитывающих физику реального мира. Это означает, что такие компании, как HD Hyundai (занимается судостроением, тяжёлым оборудованием и машиностроением), могут унифицировать и визуализировать сложные инженерные проекты непосредственно в Teamcenter X. В частности, API USD Query позволяет пользователям Teamcenter X перемещаться и взаимодействовать с физически точными объектами, тогда как API USD Notify обеспечивает автоматическое обновление дизайна и сцен в режиме реального времени. В дальнейшем Siemens планирует внедрить технологии NVIDIA и в другие продукты Xcelerator.
19.03.2024 [01:13], Сергей Карасёв
NVIDIA представила облачную платформу для исследований в сфере 6GКомпания NVIDIA анонсировала облачную исследовательскую платформу 6G Research Cloud, которая призвана помочь в разработке технологий связи следующего поколения. В число первых пользователей и партнёров по экосистеме вошли Ansys, Швейцарская высшая техническая школа Цюриха (ETH Zurich), Fujitsu, Keysight, Nokia, Северо-Восточный университет (Northeastern University), Rohde & Schwarz, Samsung, SoftBank и Viavi. Утверждается, что 6G Research Cloud предоставляет комплексный набор инструментов для внедрения ИИ в области сетей радиодоступа (RAN). NVIDIA отмечает, что платформа позволяет организациям ускорить развитие сервисов 6G, которые соединят «триллионы устройств» с облачными инфраструктурами, заложив основу для гиперинтеллектуального мира. NVIDIA 6G Research Cloud состоит из трёх ключевых компонентов. Это, в частности, подсистема NVIDIA Aerial Omniverse Digital Twin for 6G: специализированный «цифровой двойник», позволяющий физически точно моделировать системы 6G — от одной башни до масштабов целого города. Двойник включает в себя программно-определяемые симуляторы RAN и пользовательского оборудования, а также набор реалистичных свойств местности и объектов. Используя систему, исследователи смогут моделировать и создавать алгоритмы работы базовой станции на основе данных, специфичных для конкретной площадки, а также обучать модели в режиме реального времени для повышения эффективности передачи информации. 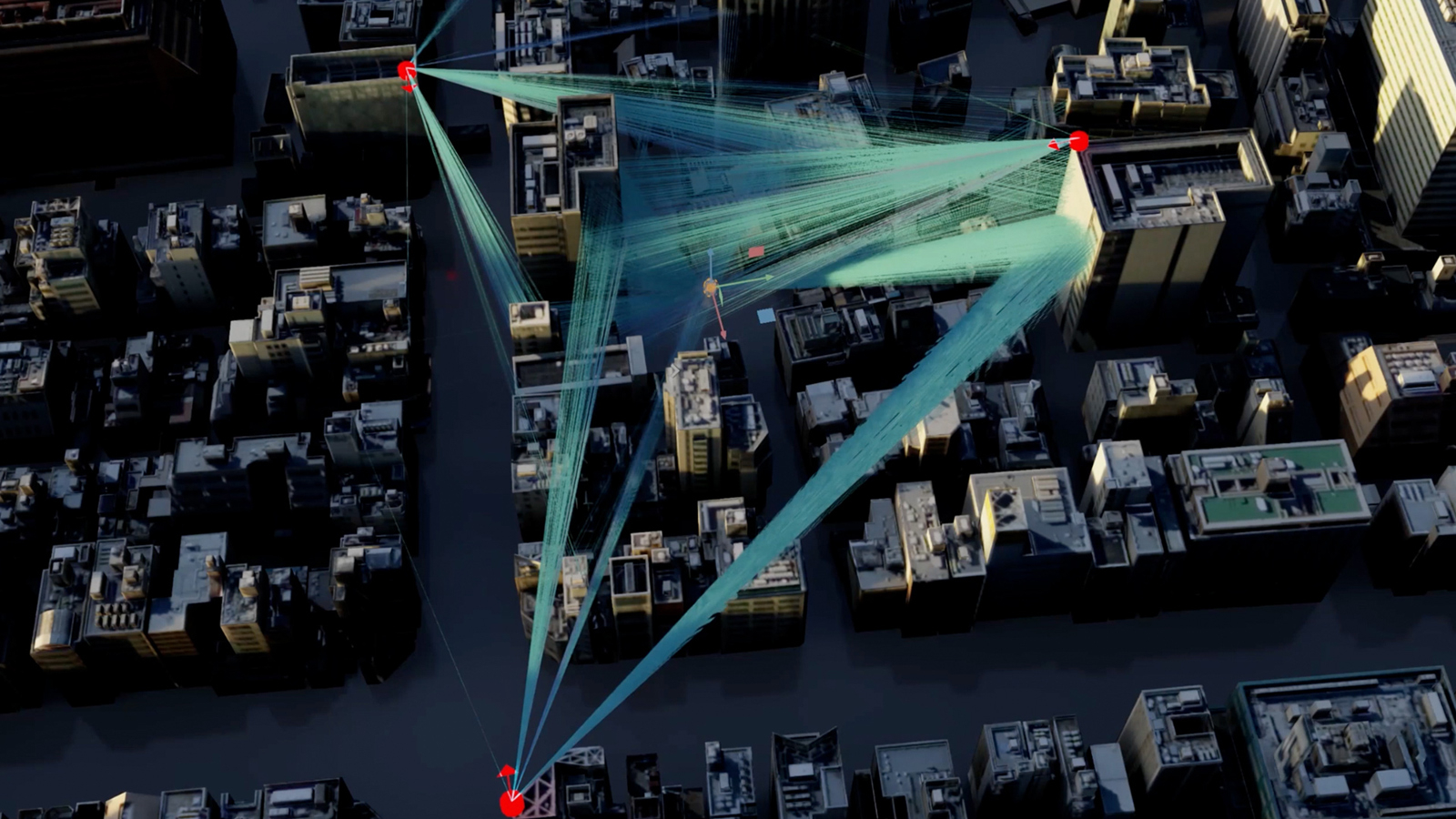
Источник изображения: NVIDIA Ещё один компонент называется NVIDIA Aerial CUDA-Accelerated RAN: это программно-определяемый стек RAN, который предназначен для настройки, программирования и тестирования сетей 6G в режиме реального времени. Третьим элементом является фреймворк NVIDIA Sionna Neural Radio Framework, обеспечивающий бесшовную интеграцию с популярными платформами, такими как PyTorch и TensorFlow. При этом задействованы ускорители NVIDIA на базе GPU для генерации и сбора данных, а также обучения моделей ИИ. Исследователи могут применять NVIDIA 6G Research Cloud для реализации различных проектов в сфере 6G. Это могут быть сервисы для автономного транспорта, интеллектуальных пространств, расширенной реальности, иммерсивного обучения, коллективной работы и пр.
19.03.2024 [01:06], Сергей Карасёв
SAP и NVIDIA ускорят внедрение генеративного ИИ в корпоративные приложенияКомпании NVIDIA и SAP объявили о расширении сотрудничества с целью ускорения внедрения генеративного ИИ в корпоративном секторе. Стороны намерены совместно развивать платформу SAP Business AI, включая масштабируемые приложения, специфичные для бизнес-сферы. Речь, в частности, идёт об облачных решениях SAP. Кроме того, будут развиваться функции генеративного ИИ в составе помощника Joule, который был представлен осенью прошлого года. Его планируется интегрировать практически во все программные продукты SAP для упрощения процесса работы и оптимизации выполнения различных задач. Отмечается, что ИИ-помощник Joule следующего поколения может быть развёрнут на площадке гиперскейлеров или в собственном облаке SAP. Он поможет клиентам раскрыть потенциал своего бизнеса, автоматизируя трудоёмкие задачи и быстро анализируя критически важные корпоративные данные. Кроме того, генеративный ИИ поможет ABAP-разработчикам. 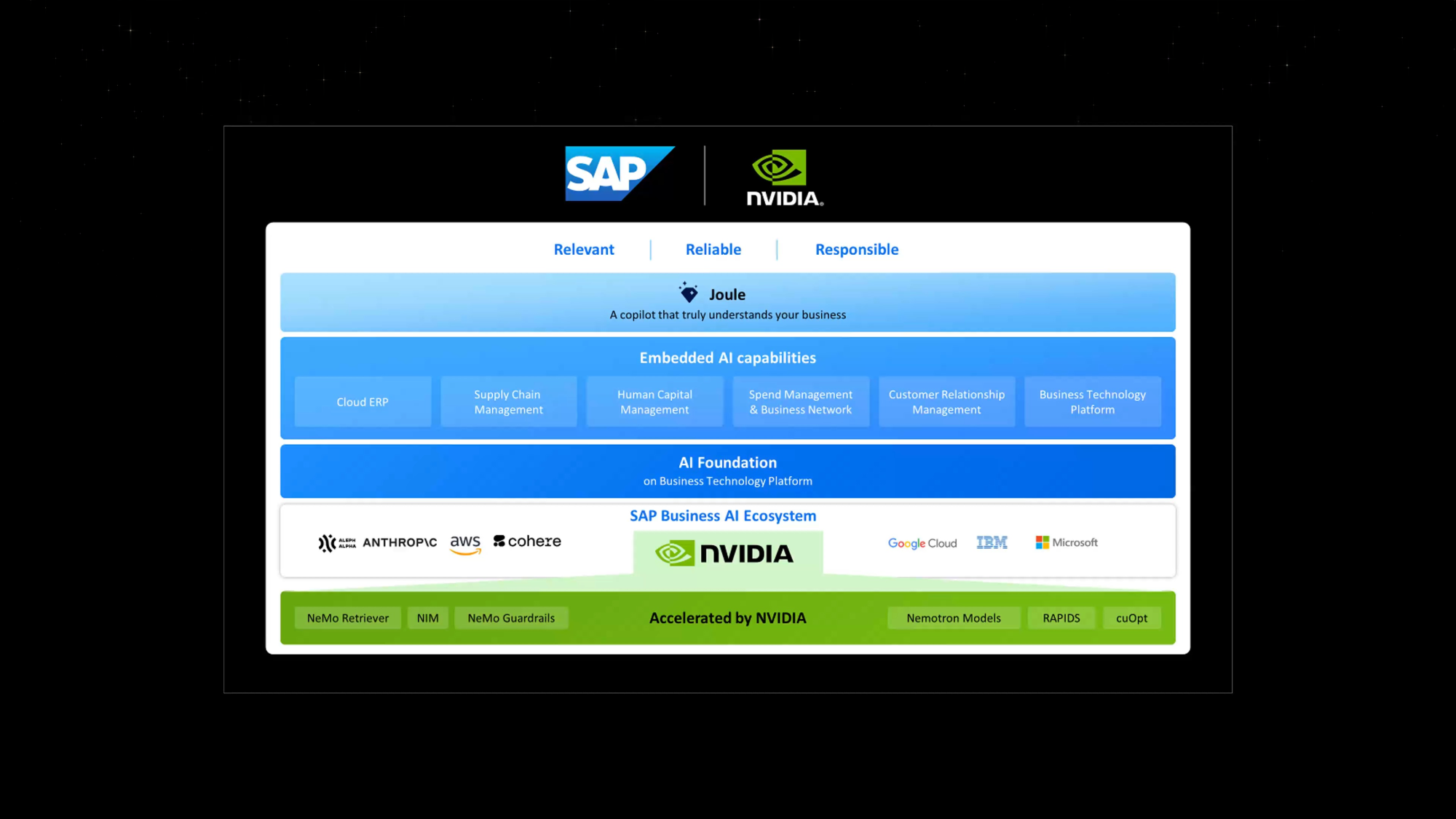
Источник изображения: NVIDIA В рамках партнёрства SAP будет использовать инструменты NVIDIA для точной настройки больших языковых моделей (LLM) для конкретных сценариев развёртывания. SAP и NVIDIA планируют представить новые интегрированные ИИ-возможности к концу 2024 года. Они затронут такие продукты, как SAP Datasphere, SAP Business Technology Platform (SAP BTP) и пр. SAP планирует задействовать облачный ИИ-сервис NVIDIA DGX Cloud AI, программное обеспечение NVIDIA AI Enterprise и базовые модели NVIDIA. В целом, SAP и NVIDIA изучают более 20 вариантов использования генеративного ИИ, в том числе для упрощения и улучшения цифровой трансформации. Это, в частности, автоматизация планирования ресурсов предприятия с помощью интеллектуального сопоставления счетов в SAP S/4HANA Cloud, улучшение сценариев использования ресурсов с помощью SAP SuccessFactors и др.
19.03.2024 [01:02], Сергей Карасёв
Ускорители NVIDIA H100 лягут в основу японского суперкомпьютера ABCI-Q для квантовых вычисленийКомпания NVIDIA сообщила о том, что её технологии лягут в основу нового японского суперкомпьютера ABCI-Q, предназначенного для проведения исследований в области квантовых вычислений. Платформа, в частности, будет использоваться для тестирования гибридных систем, объединяющих классические и квантовые технологии. Развёртыванием комплекса займётся корпорация Fujitsu. Машина расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). Ввод ABCI-Q в эксплуатацию намечен на начало 2025 года. В состав суперкомпьютера войдут более 500 узлов, насчитывающих в общей сложности свыше 2000 ускорителей NVIDIA H100. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также NVIDIA CUDA Quantum — открытой платформы для интеграции и программирования CPU, GPU и квантовых процессоров (QPU). Комплекс ABCI-Q проектируется с прицелом на возможность добавления будущих аппаратных компонентов для квантовых вычислений. 
Источник изображения: NVIDIA Ожидается, что ABCI-Q позволит проводить высокоточное квантовое моделирование в рамках исследовательских проектов в различных отраслях. Учёные смогут тестировать приложения нового типа с целью ускорения их практического внедрения. Кроме того, специалисты смогут прорабатывать передовые алгоритмы для решения специфичных задач. NVIDIA и AIST также планируют сотрудничать при разработке промышленных приложений на базе ABCI-Q. В целом, ABCI-Q является частью стратегии Японии в области квантовых технологий, задачей которой является создание новых возможностей для бизнеса и общества, а также получение выгоды от квантовых технологий, в том числе посредством исследований в области ИИ, энергетики и биологии.
19.03.2024 [01:01], Сергей Карасёв
NVIDIA показала цифрового двойника нового дата-центра с ИИ-ускорителями BlackwellКомпания NVIDIA на конференции GTC 2024 приоткрыла завесу тайны над новым вычислительным кластером, предназначенным для решения ресурсоёмких задач в области ИИ. Полностью работоспособный дата-центр продемонстрирован в виде цифрового двойника на платформе Omniverse. Показанный кластер выполнен на платформе NVIDIA GB200 NVL72. Отмечается, что проектирование и создание современных ЦОД — очень трудоёмкий процесс, который требует объединения усилий самых разных команд специалистов. При этом должно учитываться огромное количество факторов, от которых зависят энергетическая эффективность, производительность, возможность масштабирования и пр. Цифровые двойники дают возможность упростить и ускорить процесс. 
Источник изображения: NVIDIA Цифровой двойник создан на платформе Cadence Reality с применением Omniverse. Для создания цифровой копии будущего ЦОД, который заменит один из устаревших дата-центров NVIDIA, компания Kinetic Vision просканировала площадку с помощью носимого сканера NavVis VLX на основе лидара. В результате были получены высокоточные данные о физических характеристиках объекта и панорамные фотографии. Далее с помощью ПО Prevu3D была сформирована реалистичная 3D-модель ЦОД. Инженеры объединили и визуализировали несколько наборов данных САПР с высокой точностью с помощью платформы Cadence Reality. 
Источник изображения: NVIDIA Программные интерфейсы Omniverse Cloud обеспечили совместимость с другими инструментами, включая Patch Manager и NVIDIA Air. С помощью Patch Manager специалисты разработали физическую схему кластера и сетевой инфраструктуры, включая необходимые кабели с расчётом их длины. Кроме того, были рассчитаны воздушные потоки и параметры СЖО от таких партнёров, как Vertiv и Schneider Electric. NVIDIA показала, что цифровые двойники позволяют проектировать, тестировать и оптимизировать ЦОД полностью в виртуальной среде. Визуализируя производительность дата-центра, команды могут изучать различные варианты компоновки и оценивать всевозможные сценарии. Таким образом, можно добиться оптимальной структуры ЦОД ещё до создания физического объекта.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 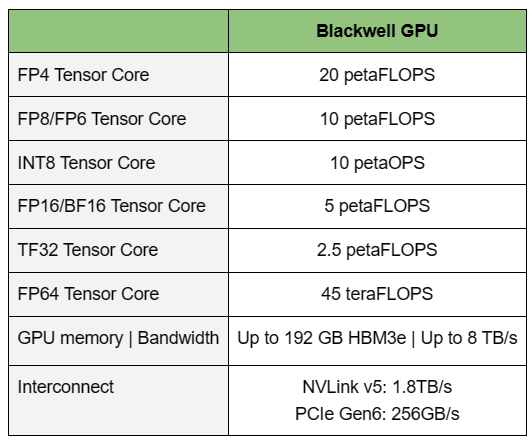 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 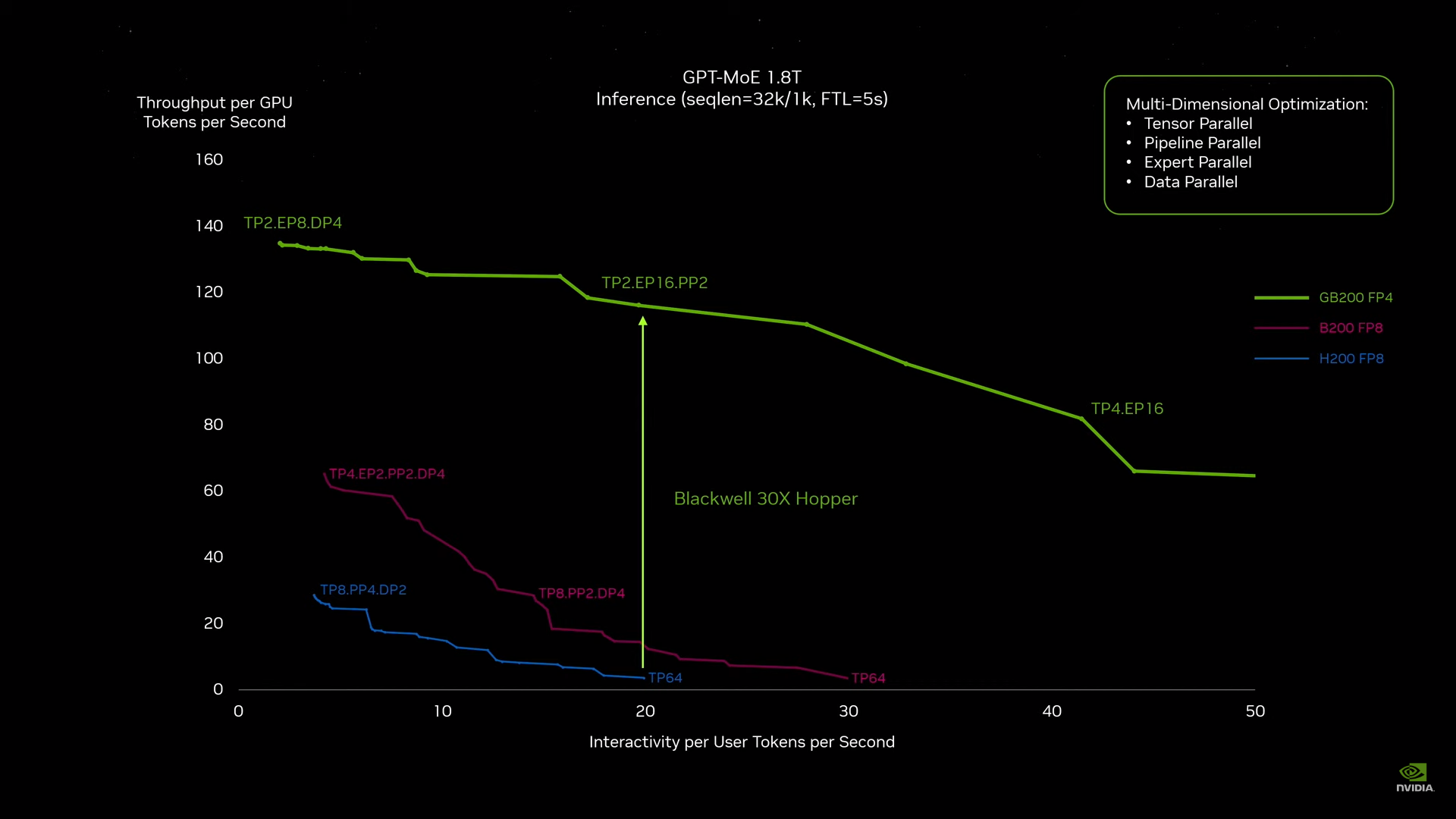 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 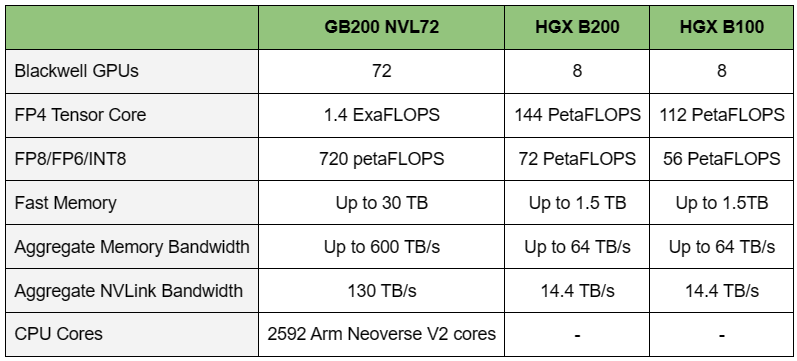 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle. |
|